
AI has changed the speed of software creation.
A simple prompt can now generate hundreds of lines of code. In many cases, it can also generate tests, suggest refactors, explain diffs, and even review pull requests.
That progress is real.
And it matters.
But it also exposes a bottleneck that already existed:
high-quality review does not scale at the same speed as code generation.
In my experience, approvals on large and complex PRs were already one of the slowest parts of delivery. AI does not remove that problem. It makes it more visible.
So the real question is not just whether AI can write code.
It is whether our review process can keep up without compromising quality.
AI has changed the speed of software creation
AI has compressed the time it takes to produce software artifacts.
What used to take hours or days can now happen in minutes:
- feature scaffolding
- test generation
- refactors
- migration drafts
- code explanations
- initial review suggestions
That is a meaningful shift.
Teams should acknowledge it clearly instead of pretending nothing has changed.
But faster generation does not automatically mean faster safe delivery.
It means the pressure moves.
The bottleneck is no longer only implementation.
Increasingly, it is review quality, approval confidence, and long-term maintainability.
That is why this is not just a story about productivity.
It is a story about whether engineering systems are adapting to a new rate of output.
Generating code is not the same as reviewing code
This is the distinction that matters most.
Generating code is often local.
A prompt asks for a feature, a refactor, a migration, or a test, and the model produces output that looks plausible and often works surprisingly well.
Reviewing code is different.
Review is not just about whether the syntax is correct or whether the implementation compiles.
It is about whether the change is right in the context of the whole system.
That review judgment includes questions like:
- Does this code fit the real business logic?
- Does it preserve hidden assumptions in the system?
- Does it break non-obvious workflows?
- Does it introduce maintenance pain later?
- Does it interact safely with production realities?
- Are the edge cases actually covered, or just the obvious cases?
That is where the gap still shows.
AI can generate a lot of code quickly.
AI can even review code against patterns, style rules, and common defects.
But that does not mean it understands the full business environment, the historical trade-offs, or the operational consequences of a subtle mistake.
This is especially true when business logic is only partly visible in code.
Some of it lives in conventions.
Some of it lives in history.
Some of it lives in exceptions, product decisions, customer expectations, support pain, regulatory constraints, or prior incidents.
A model may write code that is elegant, efficient, and testable.
And still be wrong.
Wrong because it misunderstood an exception.
Wrong because it normalized a case the product deliberately treats differently.
Wrong because it applied a generic pattern where the business needed a specific one.
Wrong because it changed semantics that only become visible in production.
That is why teams need to be careful not to confuse assistance with accountability.
Why large AI generated PRs are harder to review
Large pull requests were already difficult before AI-assisted coding.
Now the problem gets amplified.
A simple prompt can generate a lot of code very quickly.
That makes it easy to create changes that are:
- broad
- fast
- superficially polished
- difficult to inspect deeply
A single AI-assisted change can touch:
- business logic
- test files
- configuration
- APIs
- frontend behavior
- refactors across multiple files
All in one shot.
This is the difference between output speed and review capacity.
Generating 500 lines of code may take minutes.
Reviewing 500 lines properly can take much longer.
Reviewing them in context can take even longer.
Maintaining them over the next year is another problem entirely.
A reviewer is not just checking syntax.
They are trying to answer questions like:
- What actually changed?
- Is the risk obvious?
- Are edge cases covered?
- Does this fit how the system is supposed to behave?
- Will this be easy to maintain later?
The larger the PR, the more context the reviewer has to hold at once.
That slows approvals, lowers confidence, and increases the chance that shallow review slips through.
This is also where teams risk pushing complexity forward.
If AI helps ship code faster today but makes systems harder to reason about tomorrow, then some of that speed is borrowed from the future.
That debt usually does not show up immediately.
It shows up later in:
- harder refactors
- slower debugging
- brittle ownership
- inconsistent abstractions
- duplicated logic
- rising maintenance cost
- declining trust in the codebase
This is the part people sometimes describe as AI slop.
The term is crude, but the concern is real.
Some teams may be increasing delivery speed while also increasing long-term entropy.
Why AI review tools help but do not replace human ownership
There are now many AI code review tools in the market.
Some are genuinely useful.
They can help with:
- catching obvious issues
- highlighting missing tests
- suggesting edge cases
- spotting style inconsistencies
- summarizing large diffs
- accelerating initial review passes
That is meaningful progress.
It would be silly to ignore it.
But the harder question is this:
Should we trust those tools blindly and release production changes based on AI approval alone?
I do not think most serious teams are actually comfortable with that yet.
And they probably should not be.
The issue is not that AI review is worthless.
The issue is that a review approval means more than “this looks fine.”
In mature engineering environments, approval carries an implicit claim:
this change is safe enough, coherent enough, and understood well enough to move forward.
That is not a trivial standard.
And it becomes even less trivial when the code was generated quickly, spans multiple files, and touches behavior the model cannot fully understand from the local diff alone.
Tests do not fully solve this either.
Unit tests and integration tests help a lot.
They are necessary.
They should be stronger, not weaker, in AI-assisted workflows.
But they do not automatically cover every important case.
A unit test can prove a narrow behavior.
An integration test can validate a broader flow.
Neither guarantees that the system now behaves correctly across all real-world conditions.
Many edge cases are missing because:
- nobody remembered them
- they were never documented clearly
- they only show up under production load
- they depend on unusual user behavior
- they involve subtle timing or data conditions
- the team does not yet know they exist
This is where AI can create a false sense of safety.
The code looks good.
The tests pass.
The review bot says the change is clean.
And yet the system can still be wrong in ways that matter.
That is why AI review should be treated as support, not final authority.
It can improve review quality.
It should not replace human ownership.
What stacked PRs change
This is why GitHub’s Stacked PRs are interesting.
Not because they are the only answer.
And not because the tooling itself magically solves review quality.
They matter because they address the shape of the problem.
GitHub describes stacked PRs as a sequence of pull requests layered on top of each other, where each PR remains independently reviewable while still contributing to a larger change.
A simple example might look like this:
- PR 1: schema or foundation layer
- PR 2: backend logic
- PR 3: API layer
- PR 4: frontend changes
That is useful because it changes the unit of review.
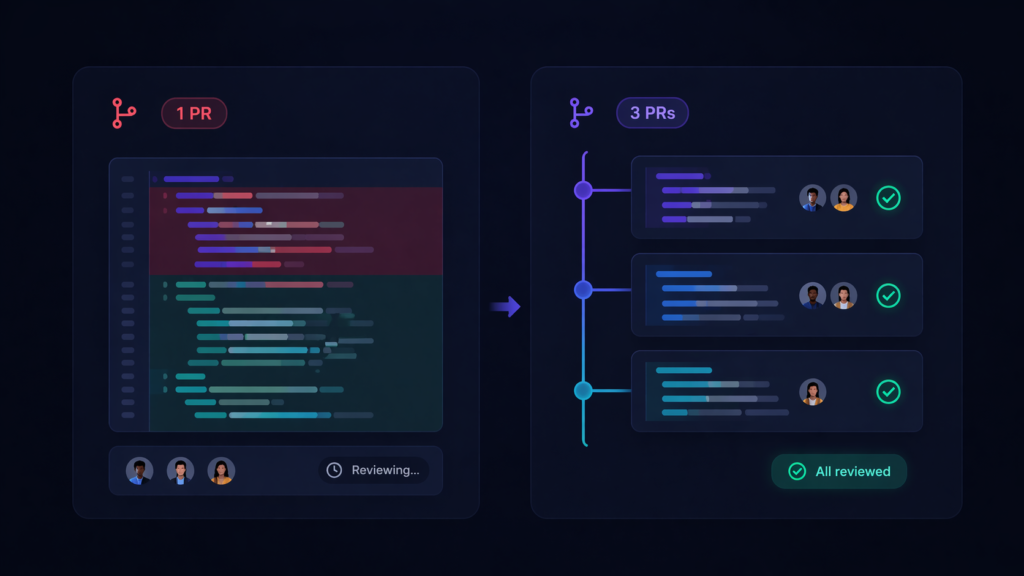
Instead of one giant AI-assisted diff, teams can structure work into:
- smaller surfaces
- clearer dependencies
- more focused approvals
- easier reasoning per layer
- better sequencing of feedback
GitHub also supports stack navigation, cascading rebases, and review context across the chain.
Those mechanics matter because good process ideas usually fail when the workflow is painful.
But the deeper idea is more important than the feature:
if code generation gets faster, review units probably need to get smaller.
That is the real insight.
Not just “use a new tool,” but “redesign the shape of review so humans can keep up.”

Human review is still the quality boundary
This is the core point.
AI can assist generation.
AI can assist review.
AI can improve developer speed significantly.
But human review is still the quality boundary for most meaningful production systems.
Why?
Because humans still hold the broader context:
- product intent
- business exceptions
- system history
- organizational risk tolerance
- architectural direction
- what “good enough” actually means in that environment
That does not mean every line must be manually written.
It means meaningful accountability still sits with humans.
And if that is true, then teams should optimize for human review quality, not just AI output quantity.
Human review is where teams decide whether faster output is turning into better software or just faster accumulation of debt.
What teams should do next
If a team is using AI heavily in software delivery, a few practical moves make sense:
1. Treat AI output as acceleration, not authority
Helpful draft material is not the same as production truth.
2. Strengthen human review on high-risk changes
Especially where business logic, money movement, permissions, customer flows, or infrastructure are involved.
3. Keep review units smaller
If generation gets faster, review surfaces should get narrower.
4. Invest in better tests, but do not confuse tests with certainty
Tests increase confidence. They do not eliminate the need for judgment.
5. Watch for hidden maintainability costs
The real bill often arrives months later.
6. Use AI review tools as support, not as sole approvers
They are useful assistants. They are not the final owners of production risk.
FAQ
AI code review is the use of AI tools to analyze pull requests or code changes and help identify likely issues such as bugs, missing tests, risky patterns, or style problems. It can improve speed and coverage, but it does not fully replace human judgment.
AI can generate broad, polished, multi-file changes very quickly. That increases the amount of context a reviewer must hold at once, which slows approvals and lowers confidence.
Not for most meaningful production systems. AI can assist review, but humans still carry business context, trade-offs, accountability, and production risk ownership.
No. They help a lot, but they do not guarantee that business logic, hidden exceptions, and unknown edge cases are fully covered.
Stacked PRs are a workflow where one larger change is split into multiple smaller pull requests that build on each other. That makes each review step smaller and easier to understand.
Because AI increases code volume faster than human review capacity. Smaller review units help teams preserve quality as generation speed rises.
The biggest risk is not only short-term bugs. It is also long-term tech debt: code that becomes harder to understand, harder to refactor, and harder to trust over time.